
这是一个创建于 111 天前的主题,其中的信息可能已经有所发展或是发生改变。
1. RAG 个人知识库和文档管理
-
很多人都会遇到以下的问题:
-
个人的技术资料和工作上累积的文档越来越多
-
PDF 、图片、文档散落在各个目录
-
想找一份资料时只能靠文件名或全文搜索
-
知道“某份文档里有答案”,但找不到在哪
-
一般来说,有大量资料和技术文档的资产的管理,要么放本地要么丢同步盘,可持久化好一些的解决方案就是部署文档管理系统管理(如 paperless-ngx 等).
那么当文档越来越多的情况下,自己已经几乎完全忘记文档内容时,如何查询和检索便成为了一个新的挑战.
随着现在大语言模型的发展,一个新的解决方向变得可行:
让电脑“读懂”你的文档,并且可以直接用自然语言提问
这就是 RAG 知识库,目前这类方案中,anythingllm 算是在强大和简单易用性中平衡的最好的产品了,而且最重要的是,部署简单和免费.
但 anythingllm 目前专注于 RAG 方向,对于原始文档的管理查找的功能有缺失,当我想在 anythingllm 中查看和管理原文档时,发现几乎难以实现,那么今天我这里探索总结的一个方案就是:
查看管理原始文档资产,并且同时同步成 AI 时代可对话、可推理的知识库
这篇文章,就是我最终探索出来的一套结合文档管理和 RAG 知识库优点个人知识库部署实践.可以方便的在 Linux 的个人服务器或者 NAS 上运行和部署.
2. 我选择了哪些组件
Paperless-ngx:文档资产管理
选择 Paperless-ngx 的原因非常明确:
-
成熟稳定
-
多文档格式支持, 有 OCR 能力( Tesseract )
-
有完整的 API 接口
-
支持规则化归档( document type / correspondent / tags )
-
完全私有化
AnythingLLM: RAG 与 Workspace 的结合体
AnythingLLM 的优势在于:
-
Workspace 抽象非常适合“知识域”
-
文档在 Workspace 中 embedding 后即可依赖 LLM 实现检索
-
可对接本地 Ollama
-
简单易上手
-
完全私有化
Ollama:本地 LLM 模型以及 Embedder
大名鼎鼎的 Ollama 就不用多介绍了,这里我们跑两个模型,qwen3-embedding:0.6b 和 qwen3:4b,供 AnythingLLM 做 Embedder 和 LLM 使用(更加强大的 LLM 提供商很多,可以自行选择)
paper2anything:我开发的一款开源的同步工具
这个工具是我为解决以上问题开发的依据 paperless-ngx 的 tag 同步到 anythingllm 的 workspace 的工具,支持多 tag 增改删的同步,项目内有详细说明,没花几天时间写代码,只是共享一下方法并不是想要推广自己的项目,但还是欢迎使用并提 issue,求 star
项目地址:
它做的事情包括:
-
调用 Paperless API 获取文档元数据
-
根据 tag 映射到 Workspace
-
通过 AnythingLLM API 上传文档和 embedding 到 Workspace
-
做增量同步(新增 / 修改 / 删除)
-
本地保存同步状态
3. 部署方法和 Docker Compose 示例
- Paperless-ngx 的部署,这是一份相对较齐全的可用配置(省略映射路径等选项):
version: "3.9"
services:
broker:
image: redis:7
container_name: paperless-redis
restart: unless-stopped
volumes:
- /your-path/redis:/data
db:
image: postgres:15
container_name: paperless-postgres
restart: unless-stopped
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: paperless
volumes:
- /your-path/pgdata:/var/lib/postgresql/data
paperless:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
container_name: paperless-ngx
restart: unless-stopped
depends_on:
- db
- broker
ports:
- "8888:8000"
environment:
# === 基础 ===
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_DBNAME: paperless
PAPERLESS_DBUSER: paperless
PAPERLESS_DBPASS: paperless
# === 管理员(首次启动)===
PAPERLESS_ADMIN_USER: admin
PAPERLESS_ADMIN_PASSWORD: admin123
PAPERLESS_ADMIN_EMAIL: [email protected]
# === 时区 & 语言 ===
PAPERLESS_TIME_ZONE: Asia/Shanghai
PAPERLESS_DEFAULT_LANGUAGE: zh-hans
# === OCR (屏蔽可能中文的 OCR 下载失败)===
PAPERLESS_OCR_LANGUAGE: eng #chi_sim+eng
PAPERLESS_OCR_CLEAN: clean
PAPERLESS_OCR_MODE: skip
# PAPERLESS_OCR_LANGUAGES: chi_sim
# === 文件命名(新语法)===
PAPERLESS_FILENAME_FORMAT: "{{ created_year }}/{{ correspondent }}/{{ title }}"
# === 性能 ===
PAPERLESS_TASK_WORKERS: 2
PAPERLESS_THREADS_PER_WORKER: 2
PAPERLESS_URL: (your domain address)
volumes:
- /your-path/data:/usr/src/paperless/data
- /your-path/media:/usr/src/paperless/media
- /your-path/consume:/usr/src/paperless/consume
-
在 Paperless 中做的事情
完成部署后,你需要做三件事:
-
创建管理员账号
-
上传文档
-
给文档设置或者分配标签
这些信息将直接决定后续知识库的结构
-
-
anythingLLM 的 docker compose 示例
version: "3.9"
services:
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
restart: unless-stopped
ports:
- "3001:3001"
environment:
# === 基础配置 ===
- STORAGE_DIR=/app/server/storage
- JWT_SECRET=your_password
- LLM_PROVIDER=ollama
- EMBEDDING_ENGINE=ollama
# === Ollama 配置(本机或同一 Docker 网络)===
- OLLAMA_BASE_URL=http://your-domain-addr:11434
# === 日志 ===
- LOG_LEVEL=info
volumes:
# === 核心数据(必须迁移)===
- /your-path/data/storage:/app/server/storage
networks:
- anythingllm-net
networks:
anythingllm-net:
driver: bridge
-
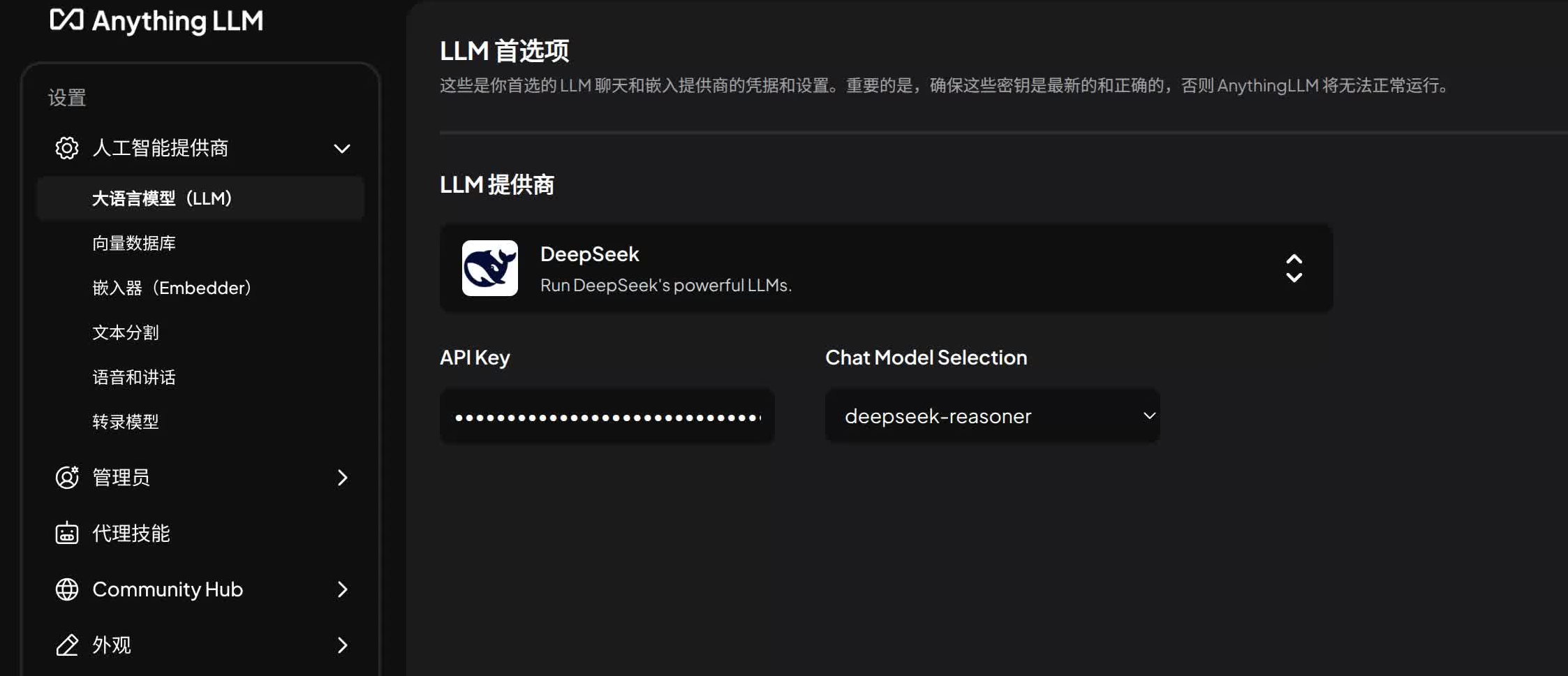
ollama 的部署和设置说明
这部分比较简单,就略过不说了,推荐 ollama 拉取 qwen3-embedding:0.6b 的模型设置到 anythingLLM 的 embedder 中,这算是 embedding 的最强模型了.
LLM 模型设置可以根据自己的条件来,本人测试 qwen3:4b 在 markdown 文档下可用,但 pdf 文档基本上就是乱答了,国内用收费模型如 deepseek 都体验不错.
-
同步设置和说明
同步工具下载地址: https://github.com/oserz/paper2anything/releases/
在同步之前,一定要先设置好 anythingllm 中的 embedder 等选项再开始同步
根据 config.json.example 中填入 url 地址,和 token 和 api_key,改名成 config.json 运行 p2a 即可
anythingllm 的 api_key 在设置 --> 开发者 API
paperless-ngx 的 token 在账户信息 --> API 认证字符串
或者运行./sync_loop.sh 即可按半小时一次更新同步内容
-
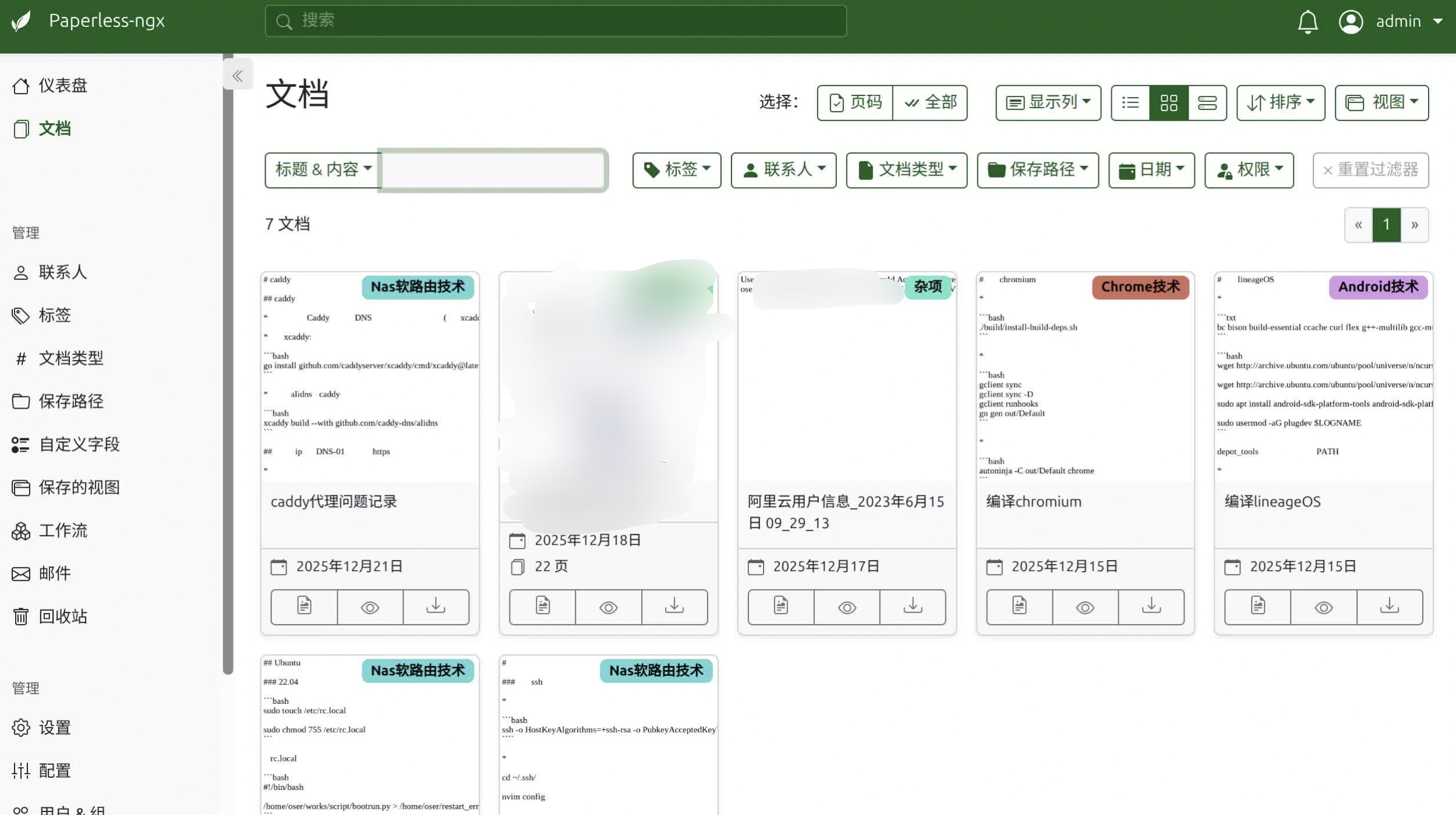
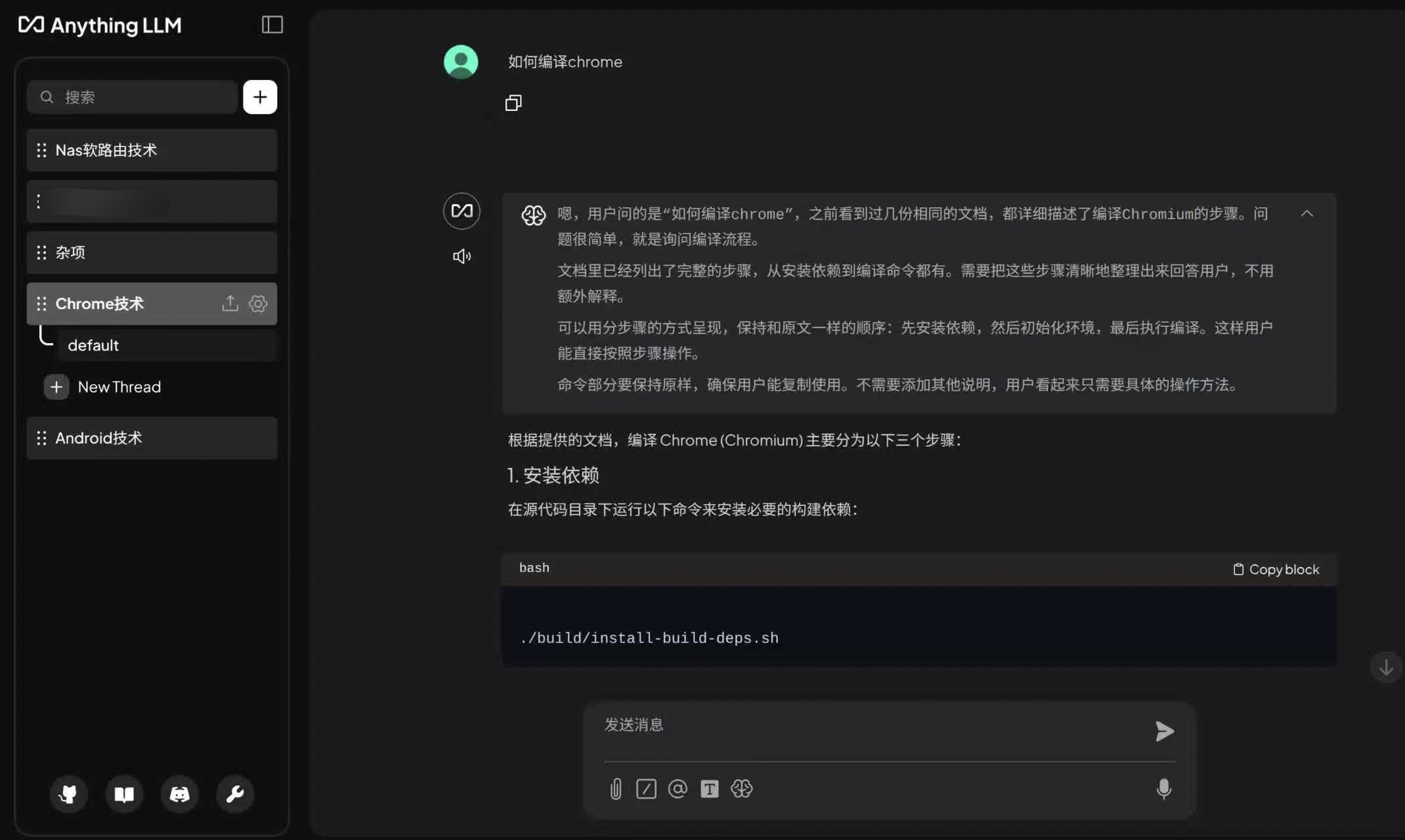
最终运行效果图:
26 条回复 • 2026-01-08 17:42:12 +08:00
1
0nJ50k88k2IAdSC2 2025 年 12 月 23 日
不用文档了,直接问 AI 了
|
 |
2
oser OP @vKv4nst4xHKXzH5B 有很多私有化的信息和总结 AI 是问不到的,这时候就需要做个人知识库了,简单举例,比如个人的密码本,工作上的文档
|
 |
3
kaizceo8 2025 年 12 月 23 日
收藏下
|

 |
5
mf2019d 2025 年 12 月 23 日
有点复杂.
|
 |
7
powerkai 2025 年 12 月 23 日
感觉不错 周末研究一下,把我家里设备的说明书都给 ai
|
 |
8
vpsvps 2025 年 12 月 23 日
希望给个具体的部署及使用步骤
很多的 joplin 笔记需要 |
 |
9
zyt5876 2025 年 12 月 23 日
没接触过很多没明白,想问问 LZ ,你这套对机器的性能要求,或者所你的机器是啥配置。
|
 |
10
AnnaXia 2025 年 12 月 23 日
之前有过类似想法,收藏下
|
 |
11
ninja543 2025 年 12 月 23 日
点赞了,想法很好,但对于懒人如我,大脑自带的 rag 就够了,狗头保命:)
|
 |
12
LiaoMatt 2025 年 12 月 23 日
腾讯 IMA, 感觉实现了 95%的功能, 开箱即用
|
|
13
oser OP |
 |
16
SmithJohn 2025 年 12 月 23 日
你这是要跟谷歌的 NotebookLM 跑同一个赛道?
|
|
17
oser OP @SmithJohn 不是的,你要说 notebookLM,可能 anythingllm 可以类比,我只是做了一点传统文档管理和 RAG 工具的同步粘合剂的微小工作而已
|
 |
18
xinqian 2025 年 12 月 23 日
有这个需求,收藏一下
|
 |
19
iX8NEGGn 2025 年 12 月 23 日
开源 RAG 现在技术成熟了吗,之前试了几款,感觉都差点意思,搜出来的东西不准不全,腾讯的 ima 确实方便效果也还行,但用着不安心。
|
 |
20
whisper1225 2025 年 12 月 23 日
@LiaoMatt 他这个自己写的文档如何导入进去
|
 |
21
litchinn 2025 年 12 月 23 日
和 WeKnora Pandawiki 是一类产品吗
|
 |
22
hmxxmh 2025 年 12 月 23 日 via Android
我也有这个需求,就是现在的 rag 知识库,都是上传了文件以后直接给你切片了,你想看原始的都找不到,需要一个文件管理平台+rag 知识库结合的项目
|
|
23
LiaoMatt 2025 年 12 月 23 日
@whisper1225 md 可以导入成笔记, 其他的只能导入知识库
|

 |
25
hpan 2025 年 12 月 24 日
兄弟搞半天 不会才知道 ima 的存在吧?
|
 |
26
patstar 1 月 8 日
和 ima 不冲突啊,个人消费者用 ima 很好,但是企业内网部署、数据隐私高的场景不就是价值吗?
另外提问楼主,使用 AnythingLLM 内置的分段、清洗策略,向量化后,检索质量如何?实际目标命中率高吗? |