
💡 创作背景:被“割裂”的搜索体验
在处理动辄几万行的系统日志或调试信息时,我们经常遇到这种场景:
某个 Bug 的触发逻辑散落在文件的不同地方。比如:
-
我需要看
UserLogin的记录; -
我需要看中间
Database的请求; -
我最后要看
Fatal Error的堆栈。
目前的痛点:
-
标准搜索(/):搜 A 就看不见 B ,想对比看只能来回按 n/N 狂跳,脑子记不住上下文。
-
Telescope / fzf-lua:虽然快,但那是为了“跳转”。即便发往 Quickfix ,界面也比较重,且不支持多次搜索结果的增量聚合。
-
正则( A|B|C ):正则太长写起来心累,且搜索过程不可逆,想临时加个关键字 D 只能重写。
✨ step-search.nvim:碎片聚合
为了解决这个问题,我写了 step-search.nvim。它的逻辑非常简单:“多次提取,自动归位”。
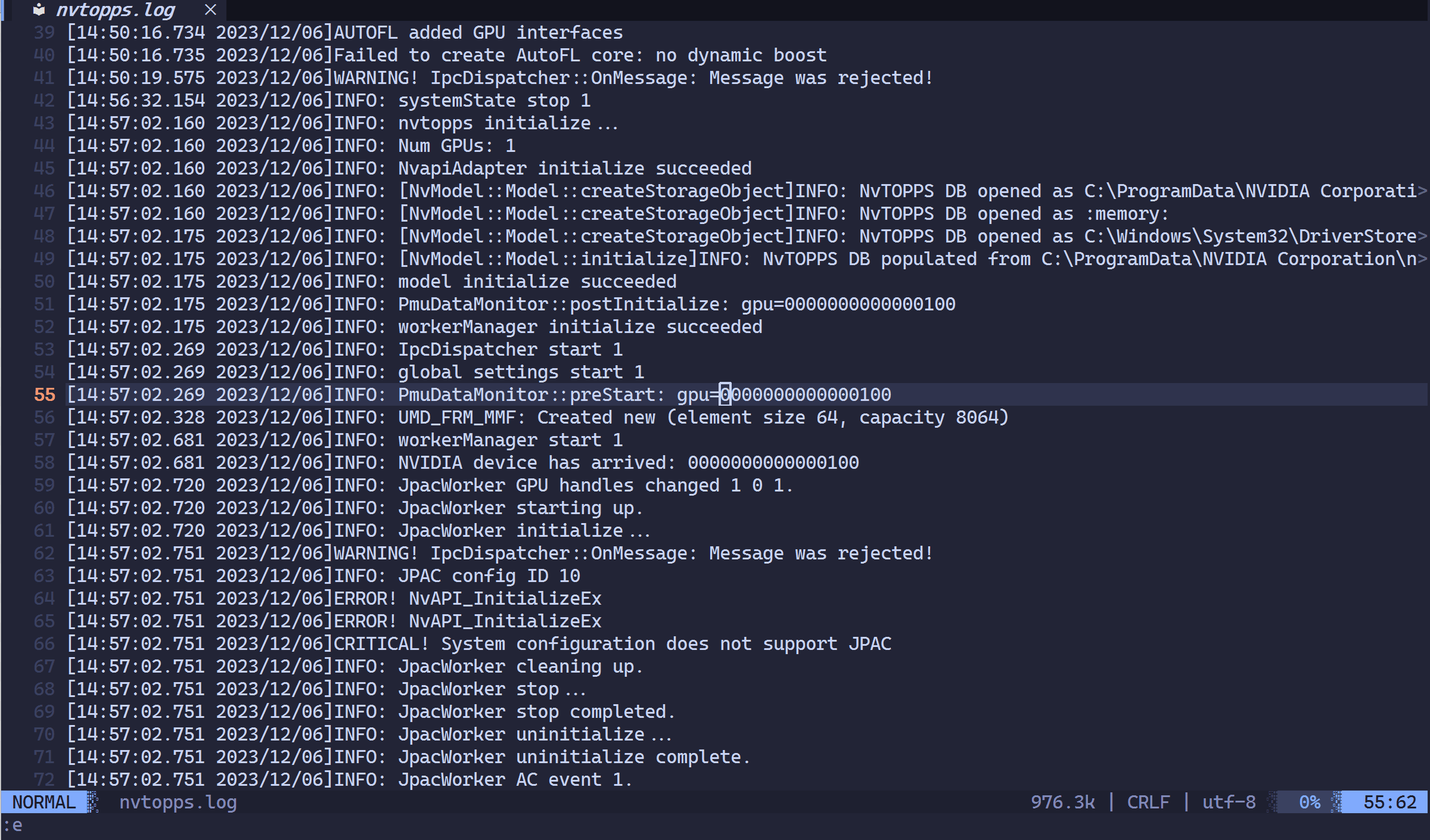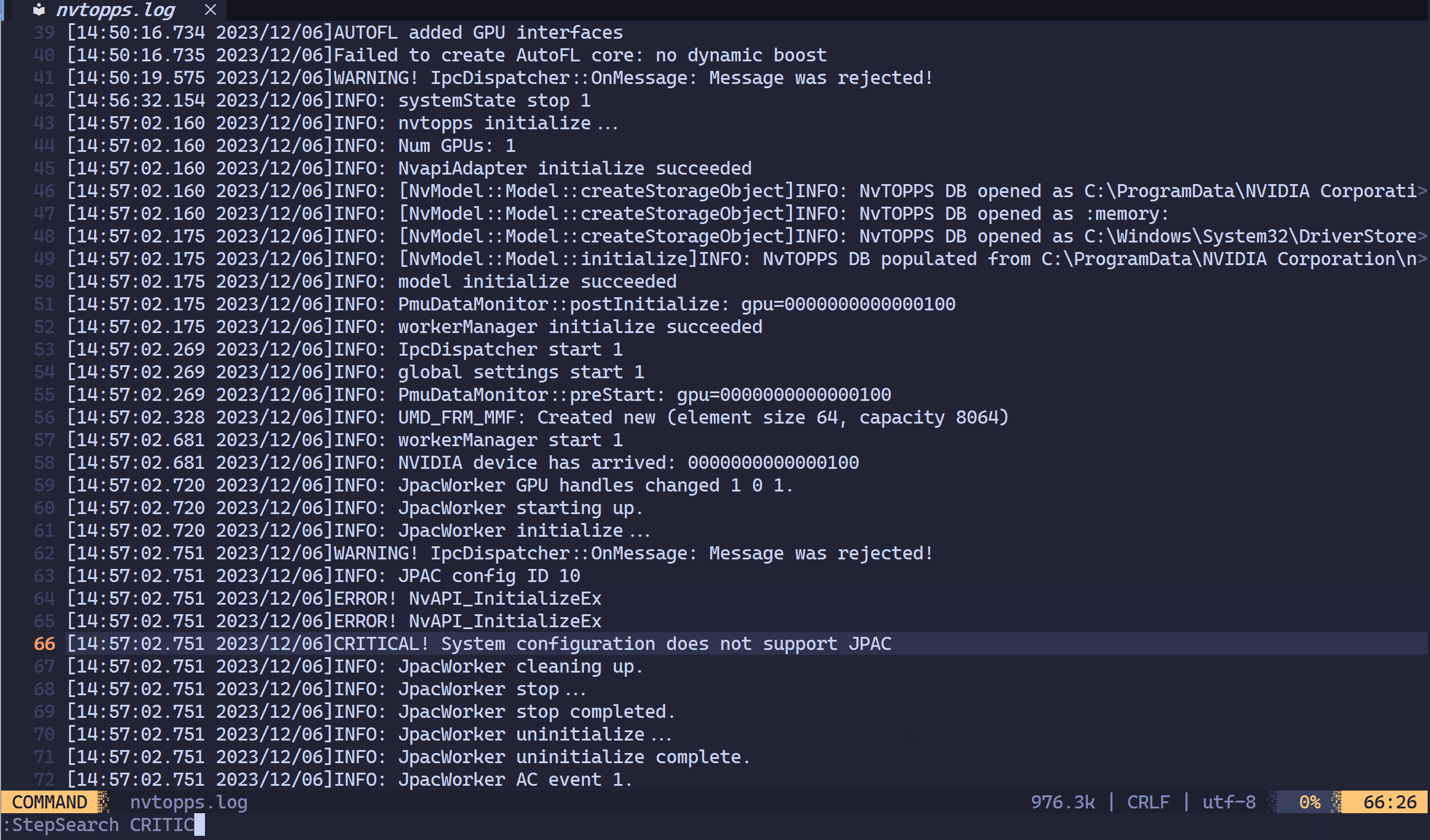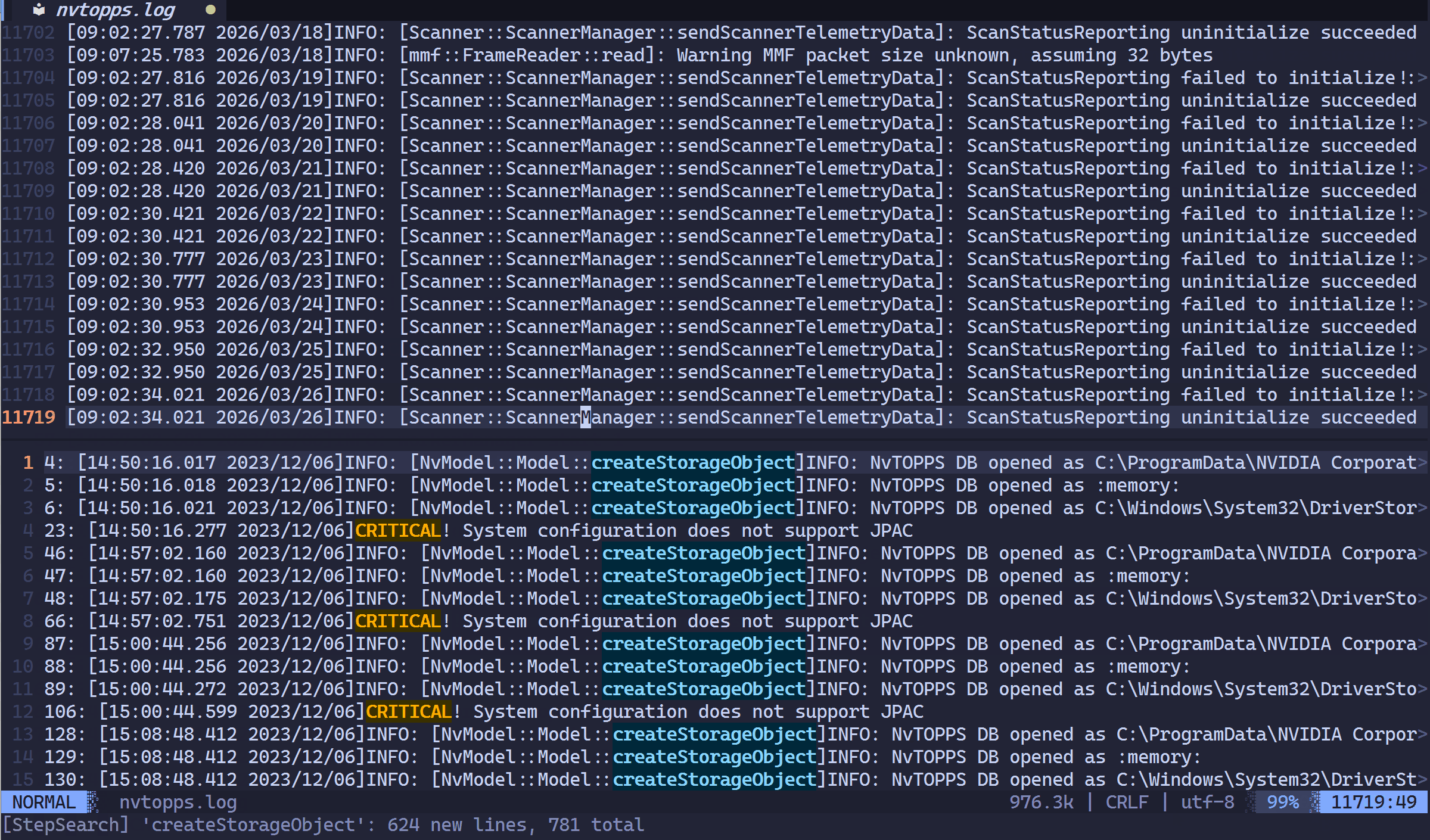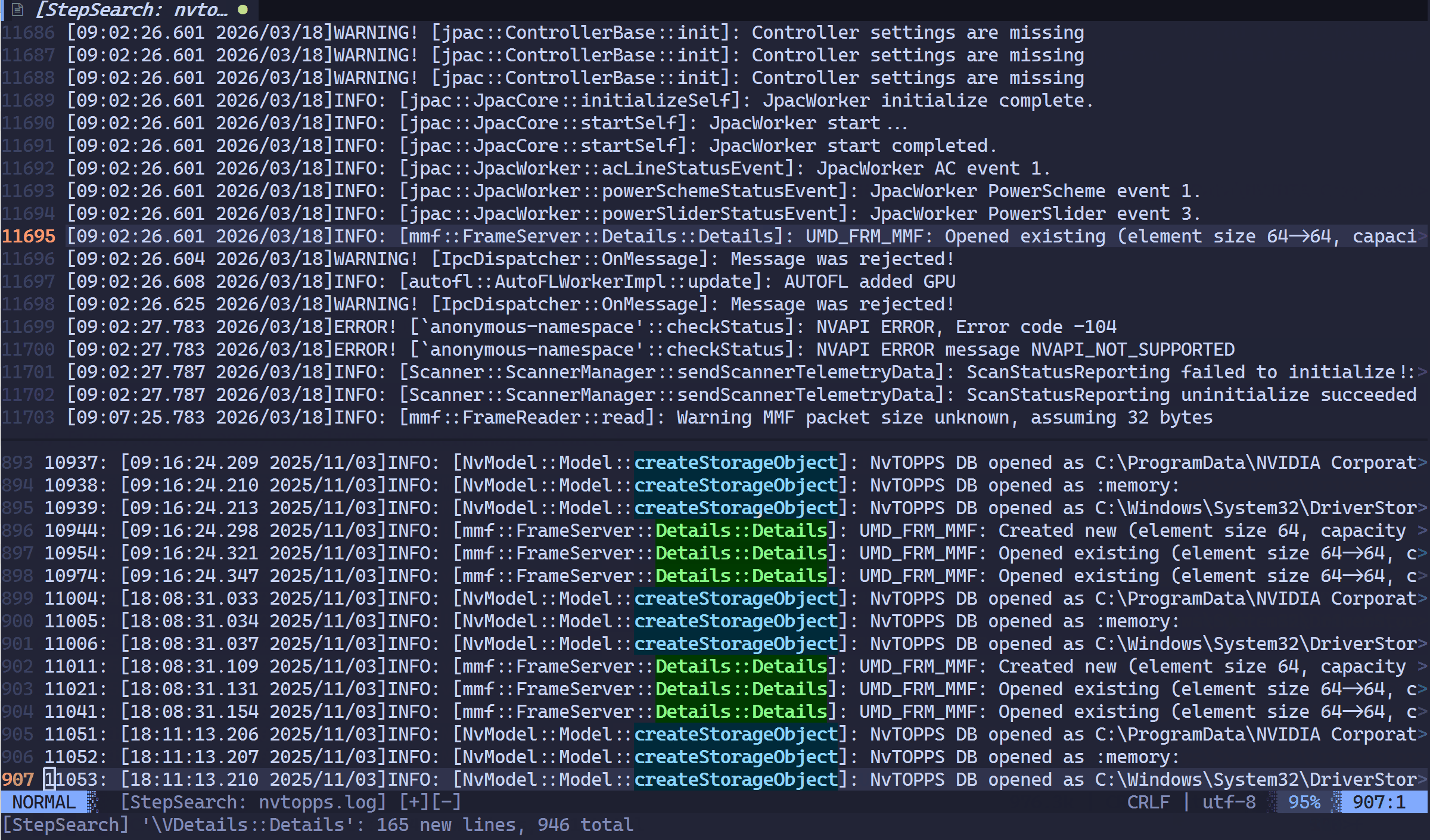
-
增量提取:你可以先搜关键字 A ,匹配行进入新 Buffer ;再搜关键字 B ,匹配行追加进去。
-
时序还原(核心):无论你先搜哪个词,插件都会根据这些行在原始文件中的物理行号重新排序。
-
效果:你会得到一个只包含你感兴趣信息的“缩影版”文件,且所有的日志点都完美地按时间线(行序)交织在一起。
🚀 项目地址
目前尚无回复