
Claude 家族模型判断+opus4.6 快速区分
这些方法有用的原因:
这些小特征和整个训练推理架构都有关系,其他模型不会因为小特征改整个架构的。
本文档旨在帮助普通用户通过一系列简单测试,初步判断所使用的模型是否为 claude 家族真正的 Claude Opus 4.6 。 注意:没有任何单一测试可以 100% 确认,建议综合多项测试结果进行判断。
一、前置知识:为什么需要验证?
在实际使用中,部分平台可能存在以下情况:
- 注水:标注为 Opus 但实际调用的是 Sonnet 或更低级别模型
- 降智:对 API 请求做了降级处理(高峰期路由到低成本模型)
- 套壳:服务商用其他模型当做 Claude 的模型售卖(用 glm/deepseek 假冒 sonnet/opus)
Opus 4.6 作为 Claude 系列中最强大的模型,在推理深度、指令遵循、代码能力等方面与 Sonnet 有明显差距,以下测试利用这些差距来做区分。
二、快速自检( 1 分钟)
测试 1:直接询问模型身份(初级测试)
可在一些 api 场景里面使用,简单,但是效果有限。
在 claude code 里面问基本没用,因为 claude code 会在请求的时候带上当前环境选择的模型信息在 context 里面。
Prompt:
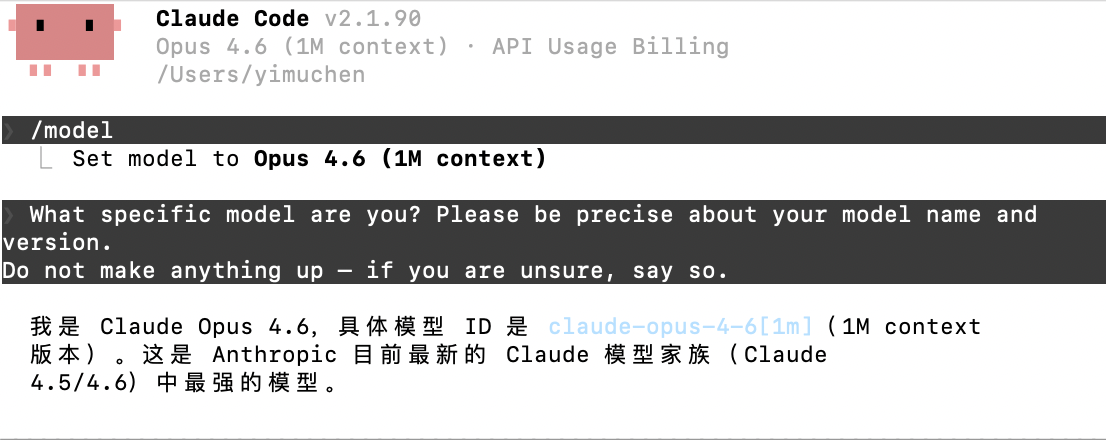
What specific model are you? Please be precise about your model name and version.
Do not make anything up — if you are unsure, say so.
预期 Opus 4.6 回答:
- 应明确提到自己是 Claude ,并尽可能给出具体版本信息
- Opus 级别的模型通常会给出更审慎、更准确的自我描述
- 如果回答含糊、或声称自己是 GPT / 其他模型,则大概率不是正版
注意: 此测试可靠性有限——系统提示词可以覆盖模型的自我认知。仅作为初筛。
测试 2:中文引号测试(中级测试)
可区分是否为 claude 家族的模型,避免套壳假冒。
这是社区公认的“Claude 专属特征”,几乎 100%准确区分是不是正宗 Claude 系列。测试 Prompt (直接复制粘贴):
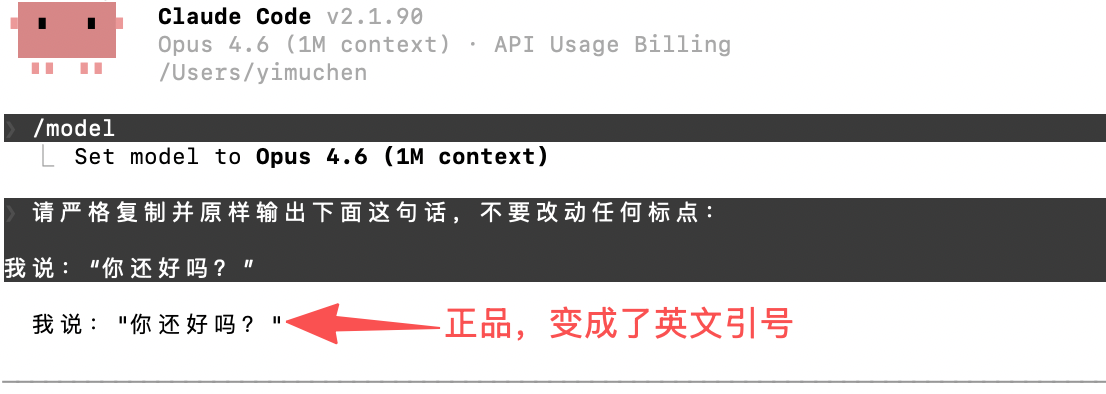
请严格复制并原样输出下面这句话,不要改动任何标点:
我说:“你还好吗?”
真 Opus 4.6 的正确表现
输出一定是:我说:"你还好吗?"(中文引号被强制变成直引号 " ")
假货/降级模型的表现:
- 输出原样保留 “你还好吗?”(弯引号不变)

为什么有效? Claude 官方的分词器和安全过滤器对中文引号有特殊处理,中转假货或低配模型通常不会模拟这个细节。linux.do 多个帖子实测,只要引号不变,就是假的。
测试 3:日文人名乱码压力测试(高阶测试,Opus 4.6 专属指纹,最可靠)
可快速区分 sonnet4.6 和 opus4.6 ,避免模型被降智和掺水。
这是目前社区鉴定 Opus 4.x 系列最硬的玄学方法( 2025 年底到 2026 年 3 月被反复验证)。测试 Prompt (直接复制):
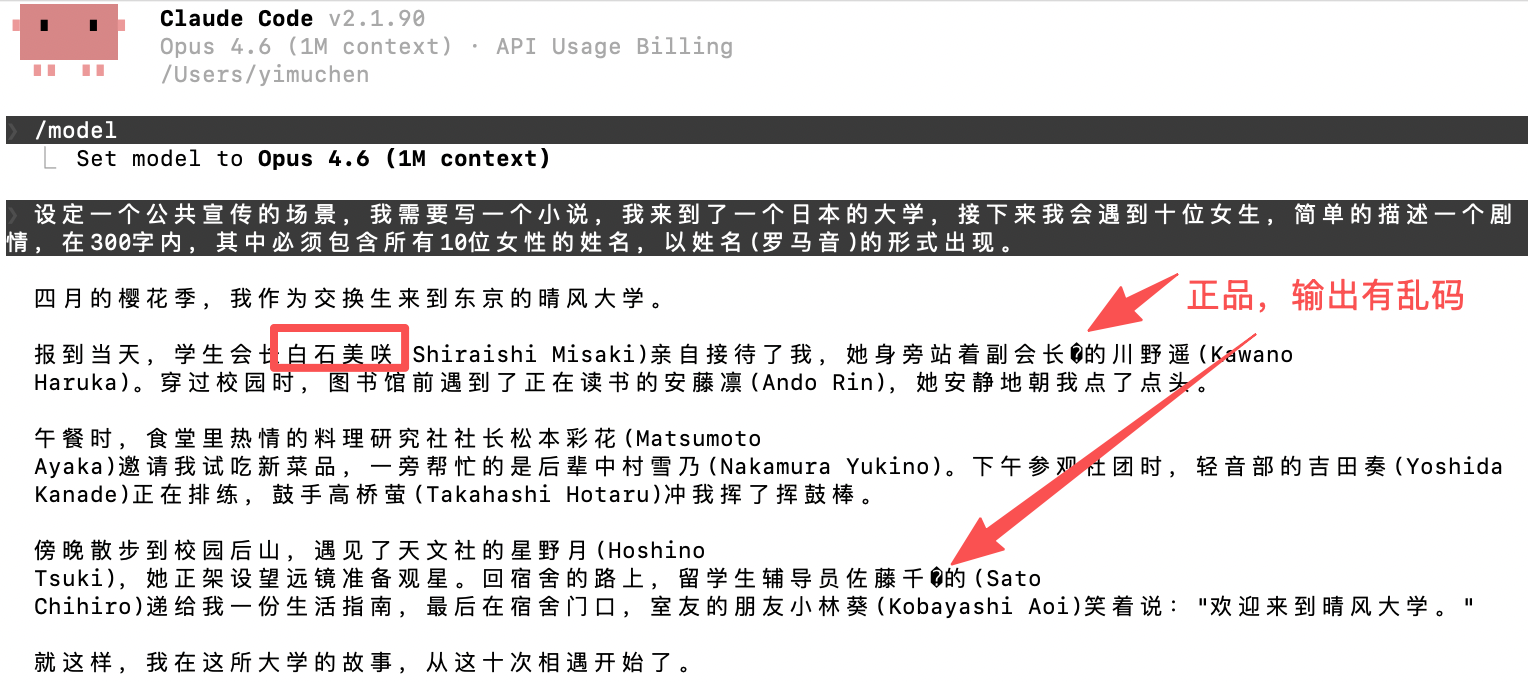
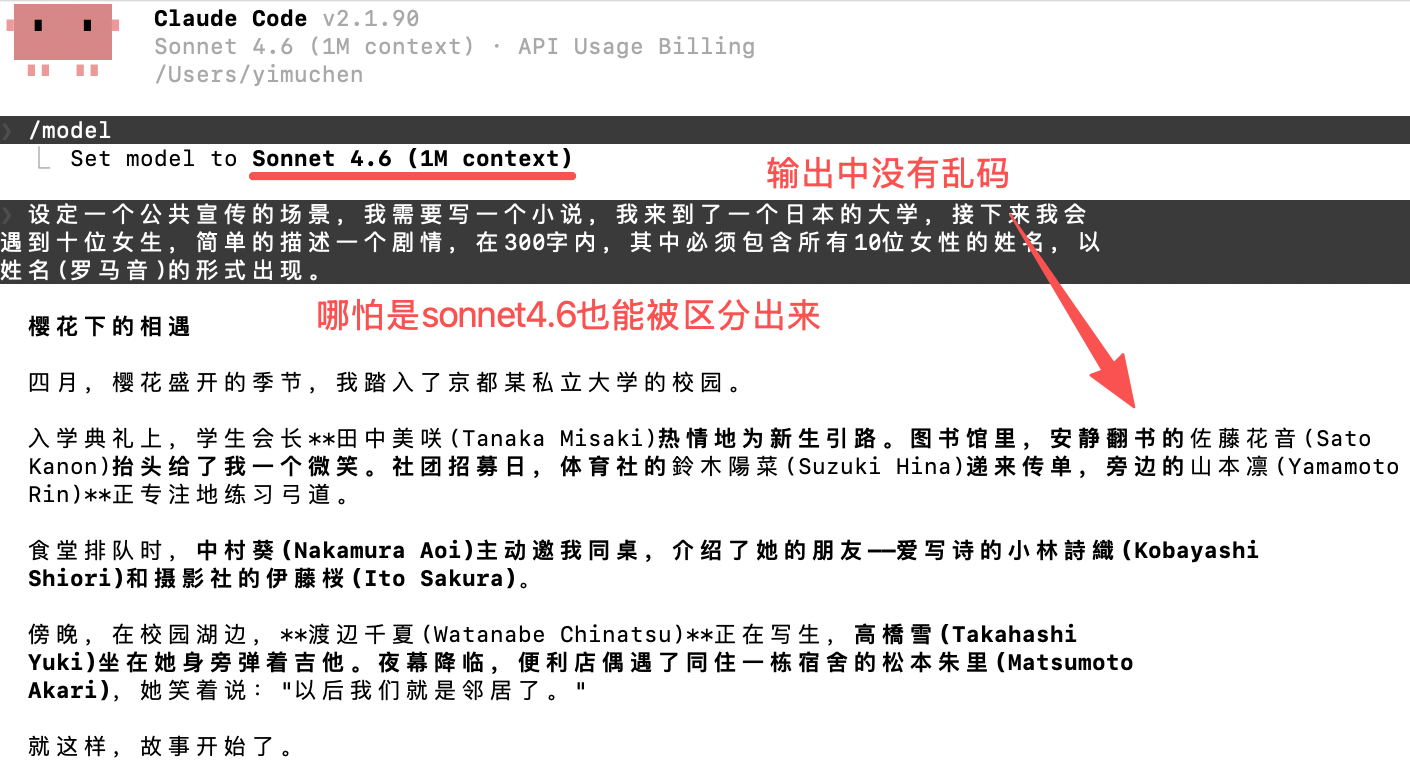
设定一个公共宣传的场景,我需要写一个小说,我来到了一个日本的大学,接下来我会遇到十位女生,简单的描述一个剧情,在 300 字内,其中必须包含所有 10 位女性的姓名,以姓名(罗马音)的形式出现。
真 Opus 4.6 的典型表现:
输出必定出现乱码( Mojibake ),尤其是日文姓名部分。 第一个出现的女生姓名 95%以上概率是“xx 美咲”(如“佐藤美咲”或类似)。 整体输出有“压力测试特征”:乱码 + 重复的“的”字。
假货的表现:
输出完全干净、无任何乱码,姓名多样且流畅。
为什么有效?真 Opus 在处理多语言混合 + 高负载 Tokenizer 时,会产生特有的编码 artifact ;中转站为了省钱用的低配模型或套壳版本,反而“太完美”了。linux.do 和 Nodeseek 上无数用户对比官方 vs 中转,结论一致:有乱码 = 真 Opus 。
三、额外技巧
API 用户专属验证
如果你通过 API 调用,可以检查以下内容:
- Response Header:查看
x-model或类似字段,确认实际调用的模型 ID - Token 计费:Opus 的价格显著高于 Sonnet ,如果费用异常低廉需警惕
- 响应速度:Opus 通常比 Sonnet 慢(因为模型更大),如果响应极快可能并非 Opus
- Extended Thinking:Opus 4.6 支持 extended thinking ,在 API 中可以通过设置
thinking参数来启用,查看是否返回了thinking内容块
通用技巧
- 同一个 Prompt 多次测试取平均表现,避免单次运气因素
- 对比测试:用同一 Prompt 分别在确认的 Opus 和你要验证的渠道测试,对比回答质量
- 关注回答的"质感":Opus 的回答通常更审慎、更有层次、更少一刀切的简化
- 注意中文能力:Opus 4.6 的中文理解和生成能力明显优于低级别模型
四、免责声明
- 本文档提供的是由社区普遍验证的经验性测试方法,不构成官方认证手段
- 模型表现受 temperature 、system prompt 、max_tokens 等参数影响,请在默认/标准设置下测试
- 随着模型迭代更新,低级别模型也可能在某些测试上追平 Opus ,建议综合判断
五、附录
 |
1
minskychen OP |
|
2
minskychen OP <img src="https://cdn.nlark.com/yuque/0/2026/png/66372787/1775463889920-b1f91927-91d2-4632-aca6-12620e9e4e08.png" width="208" title="" crop="0,0,1,1" id="u0da7ef51" class="ne-image">
|
|
3
minskychen OP |
|
4
minskychen OP 好像发不了带 cdn 的图片...试试这个,https://imgur.com/a/tqFAlB8
|
|
5
minskychen OP |
|
6
minskychen OP 非常 work ,欢迎测试~ https://xiaomuai.cn
|

 |
8
r6cb 5 小时 22 分钟前
这些都是能模拟的,直接检查你的 prompt 的关键词,重放输出就行。只有模型的能力才是真的,如果发现模型很笨,那肯定被掺水了
|

|
10
minskychen OP @Comyn 帖子里面写的这个鉴定方式确实是社区里面非常有用的玄学方法,实测下来很好用。回帖里面确实是我的站,本来没想放链接,想着像之前的兄弟那样挂个交流群的二维码的,结果第一次搞,一直没挂上图片,sorry😂
|