
简单试了下天气卡片,中文英文都试了,太简陋了:
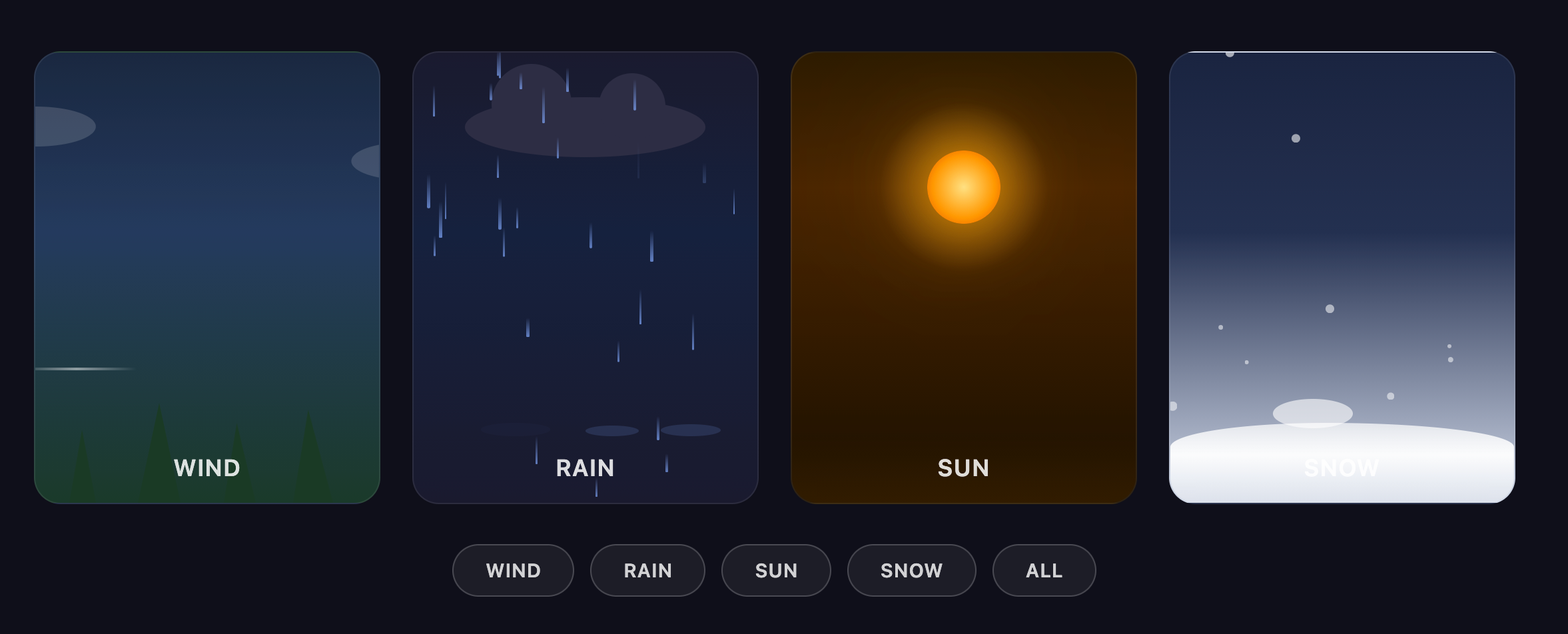
中文:
创建一个包含 CSS 和 JavaScript 的单一 HTML 文件,用于生成动画天气卡片。卡片应该通过不同的动画直观地表示以下天气状况:
风:(例如,移动的云朵、摇摆的树木或风线)
雨:(例如,下落的雨滴、形成的水坑)
阳光:(例如,闪耀的光线、明亮的背景)
雪:(例如,下落的雪花、积累的雪)
所有天气卡片应并排显示,卡片应该有深色背景。
在这个单一文件中提供所有 HTML 、CSS 和 JavaScript 代码。JavaScript 应该包含一种切换不同天气状况的方式(例如,一个函数或一组按钮)以展示每种天气的动画效果。
英文:
Create a single HTML file containing CSS and JavaScript to generate an animated weather card. The card should visually represent the following weather conditions with distinct animations: Wind: (e.g., moving clouds, swaying trees, or wind lines) Rain: (e.g., falling raindrops, puddles forming) Sun: (e.g., shining rays, bright background) Snow: (e.g., falling snowflakes, snow accumulating) Show all the weather card side by side The card should have a dark background. Provide all the HTML, CSS, and JavaScript code within this single file. The JavaScript should include a way to switch between the different weather conditions (e.g., a function or a set of buttons) to demonstrate the animations for each.
 |
1
Nzelites 6 小时 24 分钟前
有无其它 ai 的对比?
|
 |
2
dingawm OP @Nzelites #1 可以网上找找其他的看看,差距有点明显,可能 Sonnet 4.6 都不如,不过我这也只是单个测试,等后面看看有没有更多的测试吧。晚点可能再试一下 kimi2.6 ,最近用得挺多,目前感觉国产里编程写前端第一的,后端还没试。
|
 |
4
96 6 小时 18 分钟前 |
 |
6
HeyWeGo 6 小时 16 分钟前 这段时间 gemini 降智,短暂使用了 ds 一段时间,风格明显不一样。gemini 做的时候会考虑业务实际情况,会提出自己的开发,虽然大部分是顺从需求,但有些不符合业务需求的点他会提出反对或优化意见,ds 只要你提,只要能实现需求,他只会基于代码的可实现性和是否满足提出的需求去改代码,结果就是可能造成业务上的错乱。感觉就像是对真实世界知之甚少的纯开发,没有一种灵性。
|

 |
8
afkool 6 小时 16 分钟前
试了 gemini 和 gpt,大差不差。
|
|
9
dingawm OP @Nzelites #3 在一个单页表单应用的相同的 Claude 优化的一个比较完善的 Prompt 下,打败了 Gemini 3.1 Pro ,不过两个环境不一样,而且也有可能有抽卡的情况。体现在 UI 样式两个差不多,但是 kimi2.6 的问题更少,更像一个正常表单
|
 |
10
hhh12 6 小时 13 分钟前 via Android 大部分人不要以自己手头工作的体感,来判断当今几大主流 LLM 的能力。
大部分人的工作难度就是高考数学水平,你非要让陶哲轩、丘成桐、陈省身、张益唐来个大比赛, 结果分数分别是 98 、99 、97 、98 ,然后你作为高中生,还要对着卷子上的标点符号和字体强行评价一番, 完全是自取其辱。 对于绝大多数没那么抽象、逻辑没那么复杂、数理没那么相关的工作,比如调用个工具,糊个前端后端,写个 C++这些没那么复杂的任务, 最新版本的 GPT 、claude sonnet 、gemini 、kimi 、glm 、qwen 、deepseek 之间,已经没有可观测的差距了。 你所有感知到的差距,就像高考难度的题目陶哲轩 98 分和丘成桐 99 分之间的差距一样,你几乎完全 100%就是主观地在鸡蛋里挑骨头了。 就像很多人不信任何 benchmark ,20 多个 benchmark 总共几十万个 test case 看都不看, 只要一出个新模型,就自己指挥 LLM 当场写个贪吃蛇,拿七八个贪吃蛇截图,开始点评“这个贪吃蛇太绿了”、“那个贪吃蛇动画不好”,一顿侉评, 完全就是火车硬卧车厢高声点评伊朗最新局势的水准。 |
 |
14
airtee 5 小时 48 分钟前
用你提示词原风不动生成的 https://frosty-limit-6b28.svip9.workers.dev/效果
|
 |
17
Elietio 5 小时 42 分钟前
Gemini 3.1Pro
https://s3.bmp.ovh/2026/04/24/y2CjqNjL.png deepseek https://s3.bmp.ovh/2026/04/24/kDof2mfj.png |
 |
23
cctvbnm111X1 5 小时 35 分钟前
子豪:你看这个人不会用 AI 啊,提示词和 skill 都不会,快教教他吧
|
|
25
dingawm OP @cctvbnm111X1 #23 特意没用 skill
话说子豪是谁? |
|
26
Elietio 5 小时 30 分钟前 |

 |
28
mingtdlb 5 小时 24 分钟前
|
|
29
airtee 5 小时 21 分钟前
 )吃饭时候顺手做的 )吃饭时候顺手做的 |
|
30
airtee 5 小时 19 分钟前
 ) ) |
|
31
dingawm OP @mingtdlb #28 嗯嗯,我也知道是抽卡,我试了 3 次,两次中文,一次英文,界面确实有点简单,但是可能也只是前端界面审美不太行,后端啥的还没测试
|
 |
32
stefwoo 5 小时 18 分钟前
https://mp.weixin.qq.com/s/DwleBgjy3EiS7zWqlrsTEw
文中提到: 其四,不讲究的架构与 UI 。V4 基本保留了之前 DeepSeek V3 在各类架构设计上的思路,不讲究,不够精致,但也不糊弄,该有的分层,解耦,都会有。做不到 Opus 那样一看就出自大手的规范性架构。UI 方面同样如此,直出效果不算优秀,偶尔会有些精细表达,但多数时候就是基本能用的程度。甚至 high 档位偶尔下限更低,考虑不周全。如果实际开发配合设计稿,那么问题不大。但如果是纯 vibe coding ,那实现效果就需要反复抽卡。 |
 |
35
ldapadmin 5 小时 15 分钟前
你少了多少钱!
|
|
38
airtee 5 小时 10 分钟前
|
|
39
airtee 4 小时 59 分钟前
专家模式也是一个吊样,逻辑自洽都做不到
 ) ) |
 |
40
nkloveni 4 小时 59 分钟前
@hhh12 这个,消费者是上帝,提上帝提供情绪价值也是价值的一部分。另外各大模型还是有肉眼可见的风格差异的,gemini 明显管不住手,动不动就乱改文件。真实世界需求太复杂了,不是那几十万个 test case 覆盖的。
借用早期互联网一句名言,我评价个电冰箱还需要先学会制冷啊,相比音响圈水电火电玄学,大模型起码可以过双盲的。 点评伊朗的例子也不太恰当,你点评伊朗就打打嘴炮了,选谁家的大模型可以用脚投票的。claude 我只是买不起而已,要不然没有其他几家的事 |
 |
41
beyondstars 4 小时 55 分钟前
问了几个 AI 感觉也大差不差啊?
|
 |
42
TonyMontana 4 小时 52 分钟前
无所谓,反正也不会用,感觉 deepseek 更像是一种文化显现产物
|
 |
44
yvescheung 4 小时 45 分钟前
实测 DeepSeek V4 Pro 十分之拉胯,我的 7 个 AI 测试项目它打开最强的思考模式只能通过 4 个,Kimi K2.6 全部通过,MiMo V2.5 不开思考都能通过 5 个
|
 |
45
my2492 4 小时 40 分钟前
|
|
47
dingawm OP @yvescheung #44 啥测试?
|
|
48
dingawm OP @my2492 #45 第一个链接里有四个图,个人猜测:第一个 Claude 或者 Gemini 系列模型,第二个或者第四个 DeepSeek 模型(更倾向第二个是 DeepSeek 的)?
|
|
49
yvescheung 4 小时 35 分钟前
@dingawm 中英文混合文本提取指定信息,模仿已有程序接入新的 API ,阅读复杂长文档编写程序,翻译,复杂压缩包连续解压,逻辑分析,语义分析,都是我实际工作中遇到过的问题,反正就 DeepSeek 这个表现我是不可能拿来用的
|
|
51
my2492 4 小时 29 分钟前
@dingawm 我觉得 opus4.7 是最丑的,两个 4.6 的比较好,更喜欢 sonnet 的,gpt 的也挺粗糙,这是网页版里做的,调不了 effort
|
 |
52
dcatfly 4 小时 29 分钟前
claude sonnet4.6 adaptive
https://claude.ai/public/artifacts/07700983-b2cd-4811-b78e-f9eec284142e claude opus4.7 adaptive https://claude.ai/public/artifacts/c94bc886-a02c-4bf0-8b10-83a9a80bdde7 gpt5.5 进阶思考 https://chatgpt.com/canvas/shared/69eb010e42c881919c00e6529ba932ac 以上全部由楼主的中文提示词在各自的官方网页中生成,没有交互没有 skill 。 |
 |
53
snowman231 4 小时 25 分钟前
搭配 ui ux pro max 的 skill 使用,很强啊。
 |
|
54
dcatfly 4 小时 25 分钟前 @hhh12 如果“最新版本的 GPT 、claude sonnet 、gemini 、kimi 、glm 、qwen 、deepseek 之间,已经没有可观测的差距了”这句话成立,那么现在各家的价格应该相差不大了。
|
 |
55
Zzdex 4 小时 19 分钟前
|
|
56
my2492 4 小时 19 分钟前
|
 |
57
justdoitzZ 4 小时 10 分钟前
一棒子打死一个人就是这么容易
你问了一个人一个问题,这个问题,这个人回答得不是这么好,你就直接下结论了? 观察你这个发帖和结论这个过程 本身就是一种乐事,让我不禁想,你的思考链是怎么样的,hmmmm,interesting |
|
58
dingawm OP @justdoitzZ #57 前面评论有说试了 3 次,两次中文,一次英文,差不多的效果,不能算一棒子打死吧。不过新帖([/t/1208280]( https://www.0.51bbc.workers.dev/t/1208280))确实又让我对它的评价高了起来。但是奇怪的是相同的天气卡片的 Prompt ,有的顶级模型生成的效果就是好很多,而 V4 Pro 我试了 3 次效果都不太行,然后新帖子里那个例子,提示词其实并不算长,但是效果明显好太多。
|
|
59
dingawm OP |
 |
61
cyrivlclth 4 小时 1 分钟前
用楼主的提示词,在各个网页上都试过了,很随机,反正效果都大差不差,感觉跟提示词有关,提示词只要求了文件结构,对动画要求没啥约束,完全看模型心情。
|
|
62
dingawm OP @snowman231 #53 还可以,比我的那个强,但是比楼里的一些还是差点
|
|
63
dingawm OP @cyrivlclth #61 嗯嗯,是这样的,一个看模型风格,第二个是相同的模型也会抽卡。不过我第一次用 Opus 4.6 的感受就是,明明我的提示词一般(脑子里想的和输入给它的其实不完全一样),但是它就能做成我脑子里想得那样,当时确实有点震撼。
|
|
66
dingawm OP @dcatfly #52 claude opus4.7 adaptive 这个效果最好,就像我上面说的那样,Claude Opus 系列模型风格感觉就是那种明显会自己发挥更多,但是指令遵循效果也很强,做出来的效果就很惊艳
|
|
67
my2492 3 小时 56 分钟前
其实感觉不如用 gpt image 2 先做原型图,然后再交给各模型,在提示词比较模糊的情况下,直出效果十有八九是垃圾
|
|
68
dingawm OP @my2492 #64 52 楼的这个应该算最佳了吧,也很符合我对 Opus 的体感,喜欢自己发挥很多,但是也不会偏离目标
claude opus4.7 adaptive https://claude.ai/public/artifacts/c94bc886-a02c-4bf0-8b10-83a9a80bdde7 |

|
71
my2492 3 小时 50 分钟前
@dingawm 个人审美不同,不好说哪个就最好,我还是更喜欢圆角卡片。我觉得只要能把原型图给它,它能复刻得像回事,交互设计合理,就可以用了。现在我个人觉得 gpt 稍微好一点,可以设计+制作一条龙都用 gpt 生态,claude 用来交叉 review
|
 |
72
yfmir 3 小时 48 分钟前 via iPhone
其实目前相较于模型能力,更重要的是算力需求上的优化,不知道 deepseek 这次的算法优化的优化怎样
|
|
73
my2492 3 小时 46 分钟前
@dingawm 这种简单东西其实大差不差,差距还是在复杂的东西上。或者说你要做一个比较垂直领域的东西,国模在基础知识上是不如国外模型的,需要你说得很清楚才能做好,做个烂大街的东西,运气比模型本身重要。比如你完全不懂制造业,你要模型自己去做一个制造业的平台系统,国外模型就做得很好,国内模型你得给个 PRD 文档,不然他做出来的东西,能看不能用
|
 |
74
EeveeRibbon 3 小时 44 分钟前
@hhh12 #10 我认为这样的写工具卡片、写贪吃蛇这样可能是更符合实际场景的,因为大部分人只会用笼统的提示词实现自己的需求,这时候的能力就是日用的能力。而且不同模型的代码能力差异非常明显。
|

 |
76
csfreshman 3 小时 33 分钟前
@dingawm #25 除了子豪还有子轩,老年版程序员,也是 AI 生成的短剧,哈哈哈
|
 |
77
jinyan01 3 小时 26 分钟前
|

 |
79
RangerWolf 3 小时 16 分钟前
 Gemini Pro 的输出 Gemini Pro 的输出 ChatGPT Pro 的输出 ChatGPT Pro 的输出我没有看到很大的差别 |

 |
81
jukanntenn 3 小时 8 分钟前
怎么说呢,你这个评测有一点点价值,但是你表达的意思容易让人理解为你的这一个评测就直接否定了 deepseek v4 pro ,感觉他们技术报告里的评测不如你的评测权威。
|
 |
82
omi4399 3 小时 7 分钟前
 混元 3 才是真的拉了 |
 |
83
yukunZhan9 3 小时 5 分钟前
我试了一下分析一个需求,gpt5.4 联网搜索加输出 3 分钟,V4-pro 不联网光 think 能 think6 分钟的😅
|
 |
84
xiaomushen 3 小时 3 分钟前
@my2492 你确定不懂业务场景的情况下,Claude 能否做出 ready for production 的东西?
|
 |
85
lan894734188 3 小时 2 分钟前
看到 hy3 笑了
|
|
86
my2492 3 小时 1 分钟前
@xiaomushen 细节比国模强多了,那种几乎没有公开互联网资料的东西,表现明显好一大截。有意思的是谷歌这个理论上拥有最多数据的公司,在这些垂直领域知识上,远远不如 gpt 和 claude ,做出来的东西没法看
|
|
87
dingawm OP @yukunZhan9 #83 可能是算力问题
|
|
89
dingawm OP @jukanntenn #81 额,标题是有点不妥,诚恳接受你的意见。我决定将这个帖子下沉吧
|
|
90
my2492 2 小时 58 分钟前
@xiaomushen 也不是说 gpt 和 claude 做出来直接能用,但完成度高得多。国模适合做那种不需要知识储备的,比如一个公司官网、一个电商页面,这种做得挺好的。
|
 |
91
ghostman 2 小时 49 分钟前
|
|
93
xiaomushen 2 小时 42 分钟前
@my2492 也许吧,不知道如何搜集训练资料的
不过对我来说,许愿池模式没啥意义 |

|
95
ghostman 2 小时 27 分钟前
cc + frontend-design + deepseek-v4-flash
 |
|
96
ghostman 2 小时 24 分钟前
cc + frontend-design + deepseek-v4-pro
 |
 |
97
Folder 2 小时 24 分钟前
 Gemini 3.1 Pro 试了下, 感觉挺好的 |

 |
99
yueloong 2 小时 8 分钟前
 本地跑的,ollama 模型 qwen3.6:35b-a3b-coding-mxfp8 |
 |
100
soulflysimple123 2 小时 7 分钟前
|